TXTANAは本格的な本格的なコンコーダンサで、KWIC表示、頻度集計、コロケーション統計など多くの機能が付いています。
TXTANA Standard EditionとTXTANA Learning Editionの2種類があり、まったく別の検索エンジンを採用しています。
MACの改行コード対応、柔軟な行またがり検索、シノニム辞書を拡張したコンセプト辞書の搭載など、Standard
Editionの方が高機能になっています。
TXTANA Standard Edition--12,000円(税別)
機能制限無しで15日間試用可能です。
TXTANA Learning Edition--3,800円(税別)
試用可能ですが、検索件数が100件までに制限されます。
入手先:http://www.biwa.ne.jp/~aka-san/
ここでは、Learning Editionを試用します。
TXTAを使用するためには、最初に検索ファイルセットの登録を行わなくてはなりません。
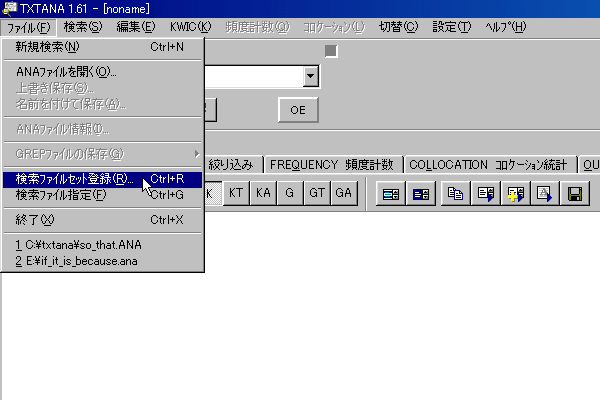
「ファイル」メニューから「検索ファイルセット登録」をクリックします。
「ファイルセット登録」画面が開きます。
ファンクションキーにファイルセットを割り当てて行きます。最初は「F1」キーになっています。
ファンクションキー表示のテキストボックスにコーパスを識別するための文字を入力します。
ここでは、試しにGUTENBERGのFTPサイトからダウンロードしたファイルをセットするので、gutenbergと入力しました。
ファイル名の指定では、直接入力しなくても、テキストボックスの右側にある「詳細」ボタンをクリックしてファイルを選択することができます。
ここでは、CドライブのMy Documentsフォルダ内にあるMy Libraryフォルダの中のテキスト・ファイルをすべて指定するために、ワイルドカードを使って「*.txt」と記入しました。
実際にテキストファイルがあるのはMy Libraryフォルダ内のetex00やetex01などのフォルダの中ですので、「サブフォルダも検索」にチェックを入れました。
さて、入力が完了したら「登録」ボタンをクリックします。
その後、F2とF3キーにそれぞれ、wshngtnpとsampleというコーパスを登録しました。
それでは、実際に検索してみましょう。
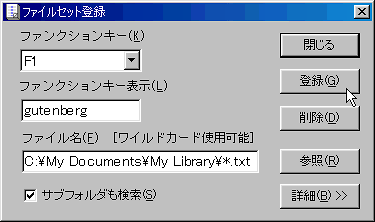
「F1」キーを押してgutenbergのコーパスを選択します。左下のステータス・バーをご覧ください。「gutenberg」ボタンがへこんでいます。
Primary Keywordのテキストボックスに検索語を「juvenile」と入力しました。
次に、横線に黄色い点がついたボタン(行またがり検索ボタン)、「A=a」(大文字小文字同一視ボタン)、「W」(単語検索ボタン)をクリックします。
GUTENBERGのテキストは行末で強制改行されています。つまりセンテンスやパラグラフの終りの他に、文の途中に改行が入っています。このような場合、行またがり検索にしないと行末の改行でセンテンスが終わったとみなされて正しい検索が出来なくなってしまいます。
また、単語検索にしないと、この文字列を含む単語がすべて検索されてしまいます。
さて、準備ができたら「GO」ボタンをクリックして検索を開始します。

検索結果がKWIC表示されました。
検索したキーワードを含む行がキーワードが真ん中に来るように検索にヒットした順に並べられています。
下側の画面にはKWIC行の参照元のセンテンスが丸ごと表示されています。
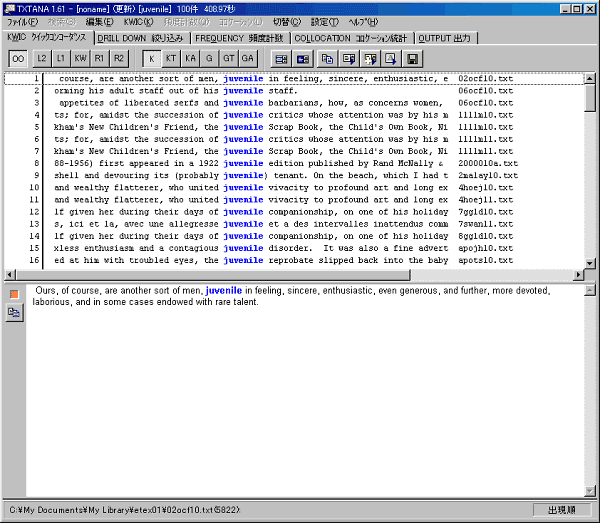
ただ検索された順に並んだKWIC行を見ていても規則性などを知ることは簡単にはできません。そこで並べ替えを行います。
TEXTANAにはキーワードの左1語目(L1)、左2語目(L2)、右1語目(R1)、右2語目(R2)でソートする機能が付いています。
試しに右1語目でソートしてみます。「R1」をクリックすると以下のような表示になりました。
このように、形容詞をキーワードにした場合、右1語でソートすると修飾する名詞にどのようなものが来るのか調べることができます。
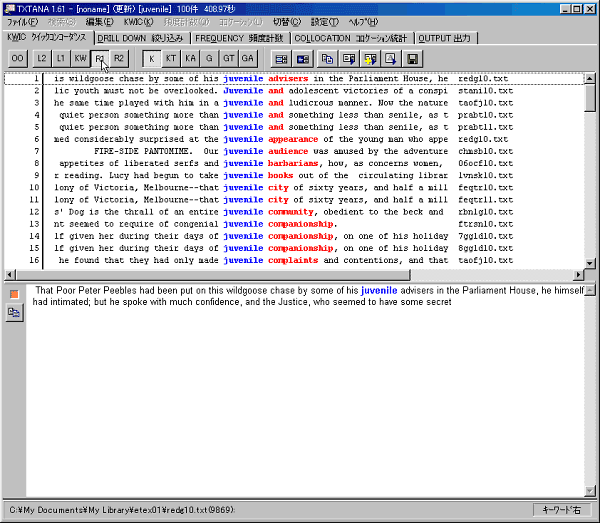
「設定」メニューから「エディタ」をクリックしエディタの設定をしておくとKWIC行から元のテキストファイルの参照部分を開くことができます。
試しに、WZエディタを設定しておいて、最初のKWIC行をダブルクリックします。
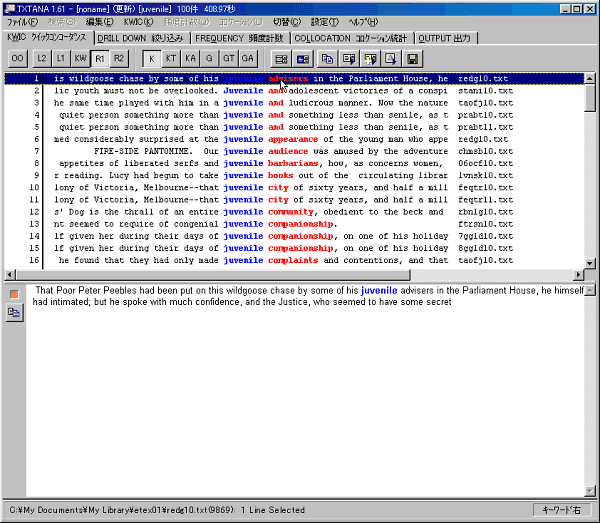
すると、WZエディタが起動し、参照元のファイルが表示されます。
ここでは、わかりやすいようにカーソルのある行にアンダーラインを表示するように設定してあります。
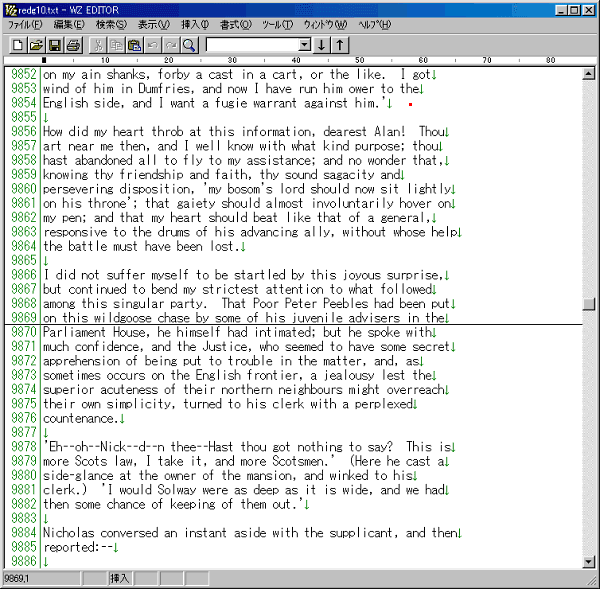
さて、もう一度TEXTANAの画面に戻って、今度は先ほど検索した結果を基にした頻度計数を試してみましょう。
「FREQUENCY」タブをクリックして頻度計数画面を表示します。
キーワードのテキストボックスの右側にある下向き三角ボタンをクリックするとプルダウンメニューが表示されます。
バックスラッシュWは単語を表します。
juvenileバックスラッシュWだとjuvenileの次に来る単語の頻度をカウントしてくれます。
「Noiseword」ボタンをクリックすると、ノイズワード・リストにある単語を排除してカウントします。
ノイズワード・リストには以下のような単語が登録されています。デフォルトでは113語ありますが、自由に変更することができます。
the
to
after
before
soon
be
for
will
thisif
not
have
as
byour
then
when
would
theyhas
there
may
about
alsoand
of
in
you
isit
are
we
or
withfrom
your
at
all
anwhat
which
any
more
dowere
been
each
into
wherethat
can
was
but
how
それでは早速、キーワードの右1語の頻度をカウントしてみましょう。
検索条件を指定して、一番左の計算機のアイコンをクリックします。
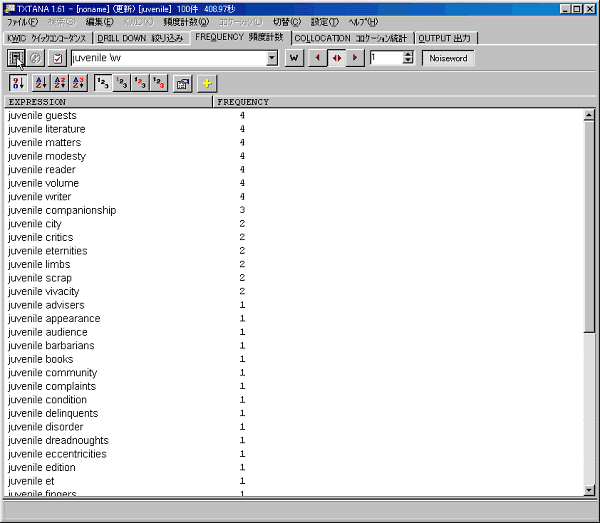
ノイズワードを除いた頻度計数の結果は以下のようになりました。
この他にも、コロケーション統計や絞り込み検索など紹介しきれないほどたくさんの機能が付いています。
TEXTANAには丁寧なマニュアル、チュートリアルが付属していますのでそれらを参考にしてじっくりと使い方をマスターしてください。
Copyright(c)2002 Babel K.K.All Rights Reserved ■月刊「eとらんす」 ■MT研究会