|
言語学で用いられるコーパスは、世界初の電子コーパスで100万語収録のBrown Corpusをはじめとして、3億数千万の語数を有するThe Bank of Englishなど数多くあります。ただ、研究発表をするわけではないので、翻訳者が使うコーパスには偏りがあっても構いません。自分専用の文例集と考えれば良いのです。
収集する文書のジャンルや種類によって様々なコーパスが構築できますが、まず基本コーパスとしてニュース英語コーパスを構築しましょう。WEB上には多数の英語ニュースサイトがあり、毎日記事が更新され、サイトによっては過去の記事がアーカイブ化されダウンロードできます。また、ニュース記事は日常生活に関するあらゆるジャンルが網羅され、誰にでもわかる文体で記述されています。
次に、英米文学のコーパスを一通り揃えておきます。版権の切れた古い作品は比較的簡単に手に入ります。あとは自分の翻訳ジャンルに関する文献を蓄積します。WEBサイトから十分なテキストが得られない場合は、スキャナとOCRを使って電子化する必要があるかもしれません。さらに、自分が翻訳したテキストはそのまま対訳コーパスとして蓄積して行きます。
スキャナとOCRを使って印刷物を電子化するのは最後の手段として、電子化されたテキスト・データをWEBサイトからダウンロードする方が現実的です。
それでは基本的コーパス構築に適したサイトをいくつか紹介しましょう。
●The Washington Post
 トップページの記事見出しから記事本文のページに入って、囲みの下の方にある「Printer-Friendly Version」をクリックすると、広告や画像のないテキストのみのシンプルなページが表示されるのでこれを保存します。これはそのままコーパス用のファイルとして使えます。最近では、このように印刷用のシンプルなページを用意しているサイトが増えていますが、コーパス作成には最適です。 トップページの記事見出しから記事本文のページに入って、囲みの下の方にある「Printer-Friendly Version」をクリックすると、広告や画像のないテキストのみのシンプルなページが表示されるのでこれを保存します。これはそのままコーパス用のファイルとして使えます。最近では、このように印刷用のシンプルなページを用意しているサイトが増えていますが、コーパス作成には最適です。
●BBC NEWS
トップページの左中ごろのSERVICES欄にあるText Onlyをクリックするとテキストのみのページが表示されます。
●CNN TRANSCRIPTS
CNNの番組で放送されたトランスクリプトのアーカイブです。トップページ左のメニューから「show transcripts」をクリックします。日にちおよびカテゴリーから一覧できます。ダウンロード・ソフトを使って一気にダウンロードしましょう。
●PROJECT GUTENBERG
お馴染のテキスト電子化プロジェクトのページです。ダウンロードは、トップページ左のメニューから「FTPサイト」をクリックすると、FTPサイトの一覧が表示されます。各サイトからは、公開年度ごとにフォルダにおさめられたファイルを直接ダウンロードできます。
| PROJECT GUTENBERGのFTP画面 |
|
 |
●The White House
トップページ左のメニューの「News」からCurrent News、Press Briefings、Proclamations、Executive Orders Radio Addressesなどがダウンロードできます。
あとは、自分の専門とする分野のWEBサイトを検索し、必要なページをダウンロードしてください。
WEB上のテキスト・データをひとつずつ手作業で保存していくのは面倒です。接続状態が悪い時にはダウンロードの途中で止まってしまうこともあります。そこで、ダウンロード・ツールを使うことにします。フリーソフトの「Iria」(作者:Wolfy)を使えばファイル名を指定するだけで高速にダウンロードできますし、中断された場合でも、レジューム機能により再度ダウンロードを継続できます。
| Iriaのダウンロード画面 |
|
 |
WEBサイトにあるファイルはプレイン・テキストではなく、HTMLファイルになっていることが多々あります。そのまま使用することもできますが、タグが邪魔な場合はタグ削除ツールを使ってプレイン・テキストにします。ただ、その場合でもHTMLファイルは保存しておいたほうがいいでしょう。後で原文のレイアウトを見たくなることがあるからです。
「HtoX32」(作者:松尾登志也氏)はフリーのタグ削除ソフトです。ドラッグ&ドロップするだけでHTMLタグを削除できます。また、EUC、JIS、SJIS、Unicode、UTF-8といった文字コードを自動判別してSJISに変換して出力してくれます。
| HtoX32の起動画面と設定画面 |
|
 |
溜め込んだコーパスをどのように使ったら良いでしょうか。基本的にはコーパスを検索してその結果を分析することになりますが、翻訳者には、言語学で行われているような複雑な統計学的手法などは必要ないでしょう。
語彙の出現頻度を調べることにより、特定ジャンルに頻繁に出現する用語を拾い出して訳語リストを事前に作成することができます。KWIC検索の結果を見ることで、キーワードの前後の語句との関連性がわかるので、英文を書く際に参考になります。GREP検索を使えば、キーワードを含む前後の文章やパラグラフを効率よく参照できるので、語句の意味を掘り下げて知ることができます。また、対訳コーパスを英文、日本文両方からGREP検索すれば英日、日英両方向の翻訳に役立てることができます。
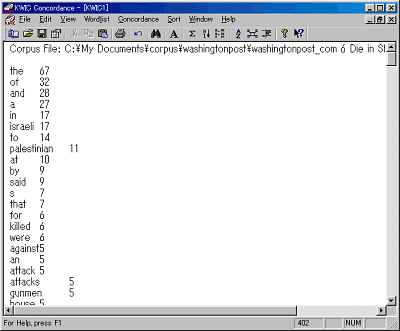
フリーソフトのKWIC Concordance for Windows(作者:塚本 聡氏)は操作が簡単な割に高機能です。試しにワードリストを出力して見ましょう。
「ファイル」メニューから「Corpus Setup」を実行し、コーパスのファイルを選択して設定します。複数のファイルを選択できます。次に「Wordlist」メニューから「Descending Wordlist」を実行すると出現頻度の高い順に表示されました。
| KWIC Concordance for Windowsのワードリスト表示画面 |
|
 |
シェアウエアのTEXTANA(作者:赤瀬川史朗氏)は本格的なコンコーダンサで、KWIC表示、頻度集計、コロケーション統計など多機能です。簡単に使いこなすわけにはいきませんが、詳細な解説書が付属していますので、じっくり取り組んで見てください。
操作方法を詳しく解説できませんが、とりあえずKWIC表示の方法を簡単に見ておきましょう。ここでは、TEXTANA
Learning Editionを使用します。
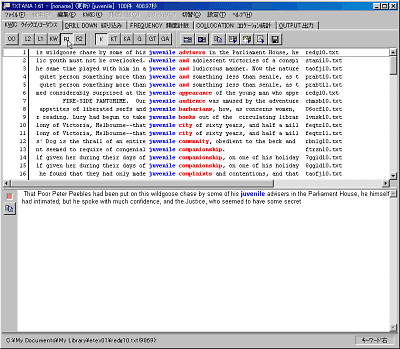
先ず、「ファイル」メニューから「検索ファイルセット登録」を実行してコーパスファイルを設定します。ファンクション・キーにファイルを割りあてることで、簡単にコーパスを切り替えることができます。コーパスの設定が済んだら、「Primary Keyword」に適当な単語を入力します。「A=a」「W」ボタンをクリックし、大文字小文字の区別をせず、検索文字列の前後にスペースを入れる設定にして「GO」ボタンをクリックすると、検索文字列が中央になったコンコーダンス・ラインが表示されます。検索文字列の前後2語をアルファベット順にソートできます。試しに右側の1語でソートするとこのように修飾する名詞が一目でわかります。
| TEXTANAソート後のKWICK画面 |
|
 |
最近では翻訳ソフトを使用する翻訳者も多くなりました。特に対訳データベース機能つきの翻訳ソフトの人気が高まっています。翻訳ソフトを「対訳コーパス作成ツール」と捉えると利用価値が数倍に高まります。
英文と日本文の電子ファイルがそれぞれある場合に、PC-Transer V9を使って対訳ファイルを作る手順を紹介します。
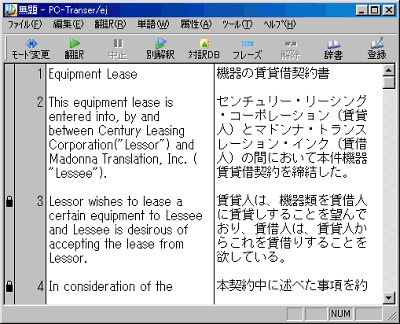
「ツール」メニューから「スクリプト」をクリックするとスクリプト一覧画面が開きます。
その中から「原文・訳文対訳読込」を選択して「実行」ボタンをクリックします。「原文ファイルの指定」「訳文ファイルの指定」画面でそれぞれのファイルを指定すると、対訳エディタに原文と訳文が読み込まれます。
| PC-Transer対訳エディタ画面 |
|
 |
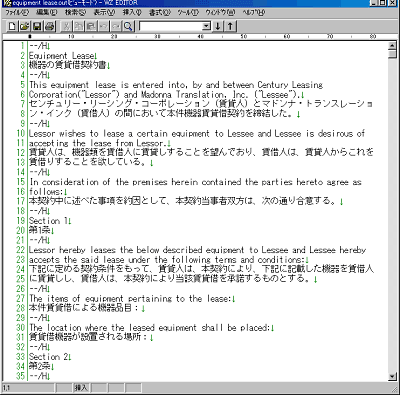
対応がずれている場合は[Enter]キー、[BS]キーあるいは「片側改行挿入」機能を使って修正します。完成したら「ファイル」メニューから「テキスト出力」を実行し、用途:対訳ファイル(.out)で保存します。これはそのままソース・ファイルになり、PC-Transerの対訳データベースにインポートすることができます。また、この対訳ファイルはテキスト・ファイルなので、テキスト・エディタで開いて検索することが可能です。
| 対訳ファイルをWZエディタで表示 |
|
 |
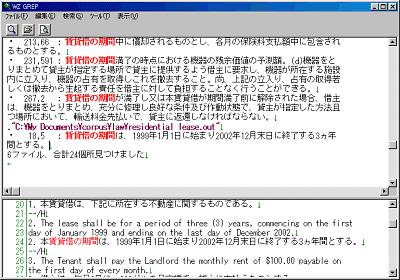
このようなテキスト形式の対訳コーパスは、WZエディタのグローバル検索(あるいは秀丸エディタのgrep検索など)を使って活用しましょう。複数の対訳ファイルを一つのフォルダにまとめて、検索ファイルをそのフォルダ内の全てのファイルに設定すれば簡易データベースのできあがりです。
早速、キーワードを入れて検索してみましょう。複数のファイルから検索語を含む行が一度に表示されました。任意の行をクリックすると参照元のファイルが開き該当の部分が表示されます。このように、訳文から検索すれば英文作成に役立てることができます。
| WZエディタのグローバル検索画面 |
|
 |
さて、電子化されたテキストを蓄積し、上手に検索して翻訳実務に役立てる方法を見て参りましたが、是非自分自身のコーパスを構築して見てください。
|