第1回 原文の読み込みと前処理 【演習】
第1回 原文の読み込みと前処理 【演習】 |
OCRの使い方 |
| 印刷物をテキスト・データにするには、イメージ・スキャナとOCRが必要です。ここでは、すでにイメージ・スキャナが接続され、セットアップが済んでいるものとします。スキャナはモノクロ、解像度400dpiに対応していれば安価なものでも十分です。 |
e.Typistエントリーの起動それでは早速、PC-Transer V10に付属している「e.Typistエントリー」を起動してみましょう。「スタート」メニュー→「すべてのプログラム」→「e.Typistエントリー」と辿っても結構ですし、最初に「翻訳ツールバー」を起動しておいて「OCR」ボタンをクリックしても良いでしょう。 これが「e.Typistエントリー」の画面です(図1)。
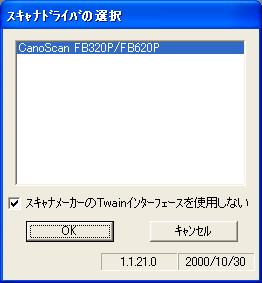
「スキャナ設定」です。「その他」メニュー→「「スキャナ設定」をクリックすると「スキャナドライバの選択」ウインドウが開きます(図2)。ここで、接続したスキャナが選択されているか確認し、「スキャナメーカーのTwainインターフェースを使用しない」にチェックを入れて「OK」をクリックします。
スキャナ取り込みスキャナに原稿をセットして、ツールバーの「スキャナ」ボタンをクリックすると「スキャナ取り込み」ウインドウが開きます(図3)。スキャン条件で「DPI」を400に、濃度はとりあえず自動にして、スキャン範囲の自動設定にチェックを入れておきます。スキャナに自動給紙ユニットがついてる場合は「スキャン方式」で「ADF取込」にチェックを入れますが、フラットベッドで1枚ずつ取り込むときは「通常スキャン」のままで結構です。濃度にはいくつかのプリセットが用意されていて、原稿の種類によって選択できます(図4)。 それではまず「プレスキャン」ボタンをクリックしてみましょう。左の画面にスキャンされた画像が表示され、スキャン範囲が青く囲まれています(図5)。 この状態ではまだ本当にはスキャンされていません。改めて「スキャン」ボタンをクリックして画像を取り込みます(図6)。 取り込む原稿が複数ページある場合は、同じ手順でスキャンします。スキャンするに従って「画像名」ウインドウに追加されます(図7)。
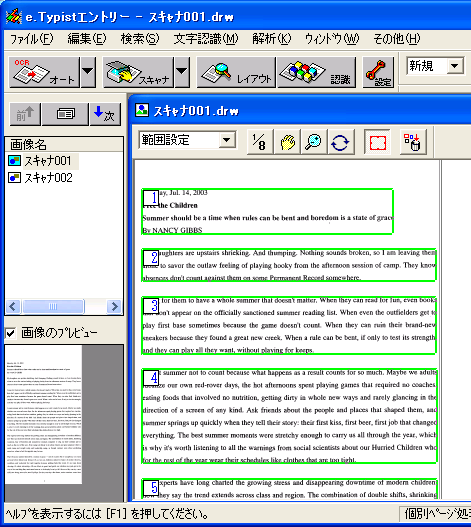
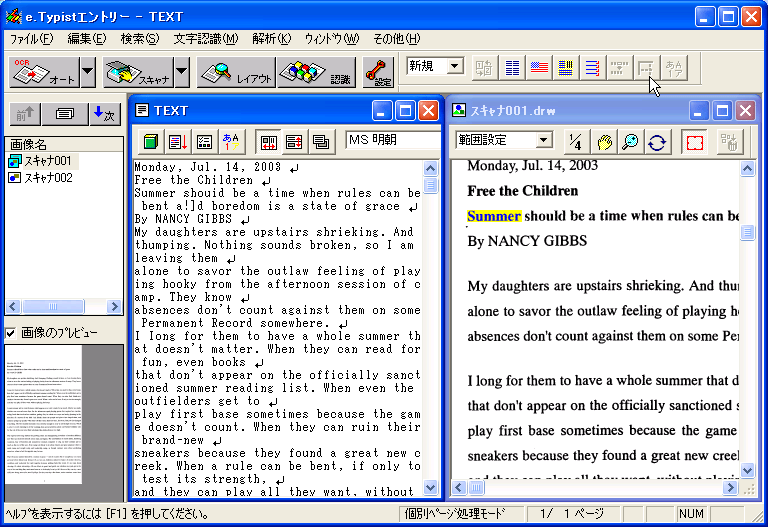
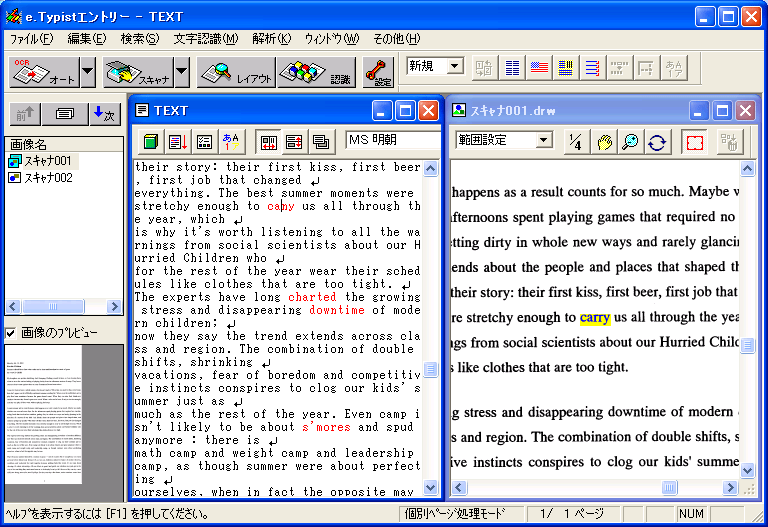
テキスト化の手順それでは1ページ目からテキストデータ化して行きましょう。「画像名」のスキャナ001をダブル・クリックしてメイン・ウィンドウの画像を1ページ目に戻します。複数ページの画像を取り込んだ直後は、最後に取り込んだ画像がメイン・ウインドウに表示されているので、必ず、1ページ目に戻してから作業を始めましょう。そうしないと、後でページの順番がわからなくなってしまうことがあります。ここでわかりやすいように縮尺を1/8にしてから「レイアウト」ボタンをクリックしてみす。自動的に読み取り範囲と順番が緑色の枠で囲まれました(図8)。 認識言語が英語になっていることを確認して「認識」ボタンをクリックすると、デフォルトでは認識結果と画像のウインドウが左右に並んで表示されます(図9)。 シンクロ・モードになっているので、テキストの任意の単語をクリックすると対応する画像の単語が黄色くマーキングされます。ここではSummerにカーソルがあります。シンクロ・モードは紙の原稿と突き合わせる手間が省けて大変便利な機能です。 ここで「全文解析」ボタンをクリックすると、誤認識と思われる単語が赤色になります(図10)。例えば、この図ではcarryがcanyと誤認識されているのがわかります。この解析結果を参考にスペルミスをざっと修正します。
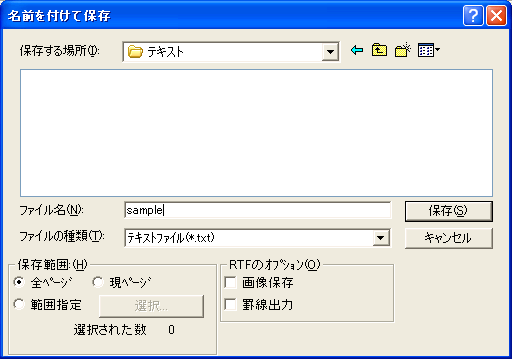
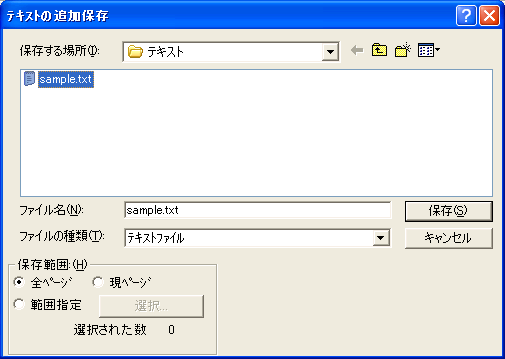
テキストの保存1ページ目のテキスト化が済んだら保存します。「ファイル」メニュー→「名前を付けて保存」で任意の名前を付けて保存します(図11)。 2ページ目以降を保存する場合は、「テキストの追加保存」を行います(図12)。 1ページ目を保存したファイルを選択して「OK」ボタンをクリックすると、ファイルの最後に追加されます。
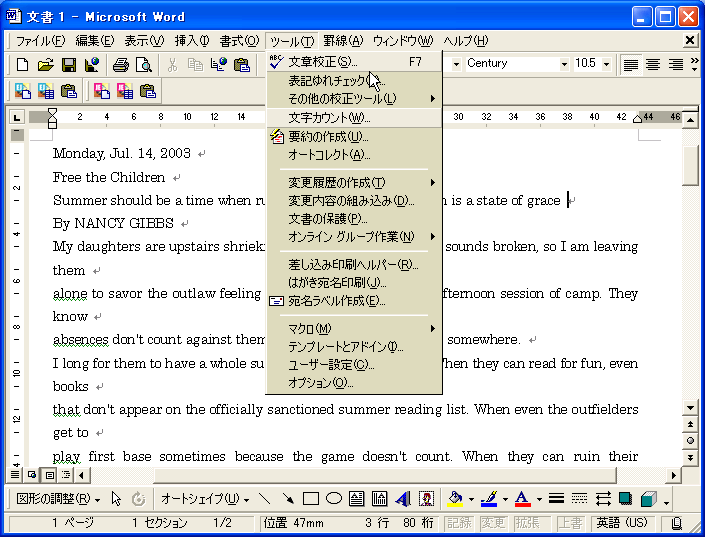
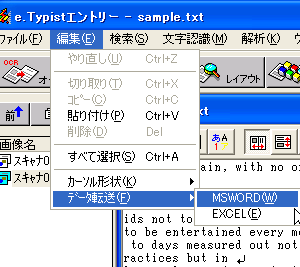
MS-Wordに転送するざっとスペルチェックをしても、実際にはもっと厳密にチェックする必要があります。最も手っ取り早いのは、日頃から使い慣れたMS-Wordのスペルチェック機能を利用することでしょう。先ほどの「テキストの保存」とは別の流れで、一旦MS-Wordでスペルチェックしてから保存してみましょう。 テキストをMS-Wordに転送するには、「編集」メニュー→「データ転送」→「MSWORD」をクリックします(図13)。 MS-Wordに転送されたら「ツール」メニュー「文書校正」をクリックしてスペルチェックを行います(図14)。 必要であればボールド、イタリック、アンダーラインなどもこの時点で追加してWord形式で保存してもいいでしょう。
|
| 電子化された原文が多くなったといっても、印刷物を迅速に電子化するスキルは必要です。そのためにはOCRは欠かせません。読み取り設定もいくつか選択できますので、いろいろと試してみましょう。 | |
| 月刊『eとらんす』 2003年11月号連動 Copyright© 2003 Babel K.K. All Rights Reserved. |
 (図2)
(図2)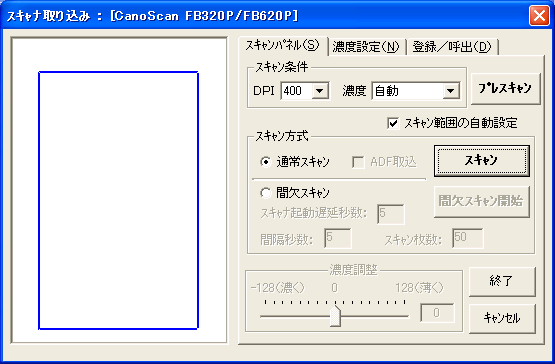
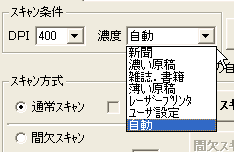 (図4)
(図4)
 (図13)
(図13)